
/* 본 게시물은 ' 나의 첫 머신러닝 / 딥 러닝 ' 의 내용과 참고자료를 토대로 작성되었습니다. */
/* 본 글은 개인적으로 공부한 내용을 정리한 글이므로 오류가 있을 수 있습니다. */
참고 자료
[URL] :
머신러닝이란?
데이터와 알고리즘을 기반으로 추론하는 프로그램으로 정의할 수 있다.
예시로 계산기는 1 + 2 의 답으로 3이 정해져있지만 머신러닝으로 1 + 2 의 답을 얻을 때 3이 아닌 다른 답이 나올 수 있다.
머신러닝(비결정론적 소프트웨어) 은 결정론적 소프트웨어로 해결하기 어려운 문제를 해결하는 방법이다. 이러한 비결정론적 소프트웨어는 스마트폰의 음성인식, 위조 지폐 판독기, 유튜브 알고리즘 등 이미 많이 상용화돼 있다.
머신러닝의 추론은 어떤 데이터를 사용하느냐 어떤 알고리즘을 사용하느냐에 따라 달라질 수 있다.
지도학습과 비지도 학습
학습이란 데이터를 특별한 알고리즘에 적용해 머신러닝 모델을 정의된 문제에 최적화하는 과정을 의미한다.
지도학습
지도학습이란 정답을 알려주면서 진행되는 학습이다. 따라서 학습 시 데이터와 함께 레이블(정답)이 항상 제공돼야 한다.
정답, 실제값, 레이블, 타깃, 클래스, y값은 다 같은 의미다. 주로 주어진 데이터와 레이블을 이용해 새로운 데이터의 레이블을 예측할 때 사용한다. 머신 러닝 모델을 통해 예측된 값을 예측값, 분류값, y hat 등으로 많이 표현한다. 테스트할 때는 데이터와 함께 레이블을 제공해서 손쉽게 모델의 성능을 평가할 수 있다는 장점이 있다. 하지만 데이터마다 레이블을 달기 위해 많은 시간을 투자해야 한다는 단점이 있다. 지도 학습의 예로는 분류와 회귀가 대표적이다.
비지도학습
비지도학습이란 레이블(정답)이 없이 진행되는 학습이다. 따라서 학습할 때 레이블 없이 데이터만 필요하다. 보통 데이터 자체에서 패턴을 찾아내야 할 때 사용한다. 레이블이 없기 때문에 모델 성능을 평가하는 데에는 다소 어려움이 있다. 하지만 따로 레이블을 제공할 필요가 없다는 장점이 있다. 비지도학습의 대표적인 예로는 군집화와 차원축소가 있다.
분류와 회귀
분류와 회귀의 가장 큰 차이점은 데이터가 입력됐을 때 분류는 분리된 값으로 예측하고, 회귀는 연속된 값으로 예측한다는 데 있다. 날씨로 예를 들자면, 분류는 덥다, 춥다와 같이 분리된 값으로 예측되는 반면 회귀는 20.4도, 25.3도와 같이 연속된 수치값으로 예측한다.
분류
분류는 데이터가 입력됐을 때 지도학습을 통해 미리 학습된 레이블 중 하나 또는 여러 개의 레이블로 예측하는 것이다.
1. 이진분류
(예, 아니오), (남자, 여자)와 같이 둘 중 하나의 값으로 분류
2. 다중분류
(빨강, 녹색, 파랑) 중 하나의 색으로 분류, 0 부터 9까지의 손글씨 숫자 중 하나의 숫자로 분류하기처럼 여러 개의 분류값 중에서 하나의 값으로 예측해서 분류
3. 다중 레이블 분류
데이터가 입력됐을 때 두 개 이상의 레이블로 분류할 경우 다중 레이블 분류라고 한다. 예를 들어, 분류값으로 세모, 네모, 동그라미가 있을 경우 세모와 네모의 도형이 입력값으로 들어오면 다중 레이블 분류 모델의 예측 값은 (세모, 네모)가 되고, 다중 분류 모델일 경우 세모와 네모 중에서 더 높은 확률을 지닌 레이블로 예측한다.
회귀
회귀는 입력된 데이터에 대해 연속된 값으로 예측한다.
과대적합과 과소적합
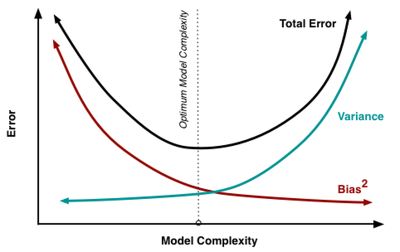
데이터에서 충분히 특징을 찾아내지 못하고 머신러닝 모델을 학습할 경우 모델이 과소적합되기 쉽고, 필요 이상의 특징으로 학습할 경우 과대적합되기 쉽다.
수학적으로 데이터에서 특징을 필요 이상으로 추출할 경우 분산(variance)이 높아지고, 반대로 필요 이하로 추출할 경우 편향(Bias)이 높아진다. 에러율이 가장 적은 모델, 즉 최적의 모델은 분산과 편향이 균형된 모델인 것을 알 수 있다. (편향과 분산이 궁금하다면 다음 글을 참고하길 바란다.)
학습데이터 예시
| 사물 | 분류값 | 생김새 | 크기 | 줄무늬 |
| 테니스공 | 공 | 원형 | 중간 | O |
| 야구공 | 공 | 원형 | 중간 | O |
| 농구공 | 공 | 원형 | 큼 | O |
| 딸기 | 과일 | 세모 | 중간 | X |
| 포도알 | 과일 | 원형 | 작음 | X |
과소적합
과소적합은 모델 학습 시 충분한 데이터의 특징을 활용하지 못할 경우 발생한다. 위 학습 데이터 예시를 바탕으로 과소적합을 설명해보자. 만약 생김새 만으로 공/ 과일을 분류할 수 있을까? 우리는 생김새만으로는 동그라미 -> 과일이라는 간단한 머신러닝 분류기를 만들 수 있다. 하지만 이 분류기는 높은 정확도를 가지지 못할 것이다. 그 이유는 공을 구별할 수 있는 특징이 너무 적기 때문에 현재 가지고 있는 데이터에 대해서도 정확도가 낮을 것이며, 앞으로 추가할 데이터에 대해서도 높은 정확도를 예상하기 어렵다. 이처럼 충분하지 못한 특징만으로 학습되어 특징에만 편향되게 학습된 모델을 과소적합된 모델이라고 부른다. 보통 테스트 데이터뿐만 아니라 학습 데이터에 대해서도 정확도가 낮게 나올 경우 과소적합된 모델일 가능성이 높다.
과대적합
학습 데이터에서 필요 이상으로 특징을 발견해서 학습 데이터에 대한 정확도는 상당히 높지만 테스트 데이터 또는 학습 데이터 외의 데이터에는 정확도가 낮게 나오는 모델을 과대적합된 모델이라 부른다. 마찬가지로 위 학습 데이터 예시를 바탕으로 과대적합을 설명해보자. 테니스공, 야구공, 농구공 데이터로 머신러닝 모델을 학습할 경우 '생김새가 원형이고 크기가 작지않으며, 줄무늬가 있으면 공이다' 라는 명제를 가진 머신러닝 모델을 만들 수 있다. 이 머신러닝 모델은 현재 가지고 있는 학습 데이터에는 100% 의 정확도를 보여주지만 학습 데이터에 포함되지 않은 아래의 테스트 데이터에는 0%의 정확도를 갖는다. 머신러닝 모델이 학습 데이터에는 높은 정확도를 가지나 테스트 데이터 또는 실제 데이터에 대해서는 낮은 정확도를 보일 경우 과대적합을 의심할 수 있다.
과대적합을 피하기 위한 가장 좋은 방법은 많은 데이터를 확보해서 부족한 학습 데이터를 충분히 채우는 것이다. 하지만 데이터가 충분하지 않고 모델이 과대적합됐을 경우 학습에 사용된 특징을 줄여보는 것도 좋은 방법이다. 또한 특징들의 수치값을 정규화 함으로써 특정 특징에 의한 편향을 줄이는 것도 과대적합을 피하는 좋은 방법 중 하나이다. 그 외에도 딥러닝 같은 경우 조기 종료 및 드롭아웃을 사용해 과대적합을 피할 수 있다.
정리
- Bias(편향)과 Variance(분산)은 상호 Trade-off 관계에 있어서 이 둘을 모두 잡는 것은 불가능 한 딜레마가 생긴다.
- 편향과 분산이 균형된 모델이 최적의 모델이다.
- Bias(편향)가 높아지는 것(과소적합)은 많은 데이터를 고려하지 않아 (=모델이 너무 단순해) 정확한 예측을 하지 못하는 경우를 말한다
- Variance(분산)이 높아지는 것(과대적합)은 노이즈까지 전부 학습해(=모델이 너무 복잡해) 약간의 input에도 예측 Y 값이 크게 흔들리는 것을 말한다.


