
/* 본 게시물은 ' 파이썬 라이브러리를 활용한 데이터 분석 2판 | with 웨스 맥키니 ' 의 내용과 참고자료를 토대로 작성되었습니다. */
/* 본 글은 개인적으로 공부한 내용을 정리한 글이므로 오류가 있을 수 있습니다. */
Numpy ndarray: 다차원 배열 객체
Numpy의 핵심 기능 중 하나인 ndarray는 N차원의 배열 객체이다. 이는 파이썬에서 사용할 수 있는 대규모 데이터 집하블 담을 수 있는 빠르고 유연한 자료구조이다.
1. ndarray 속성
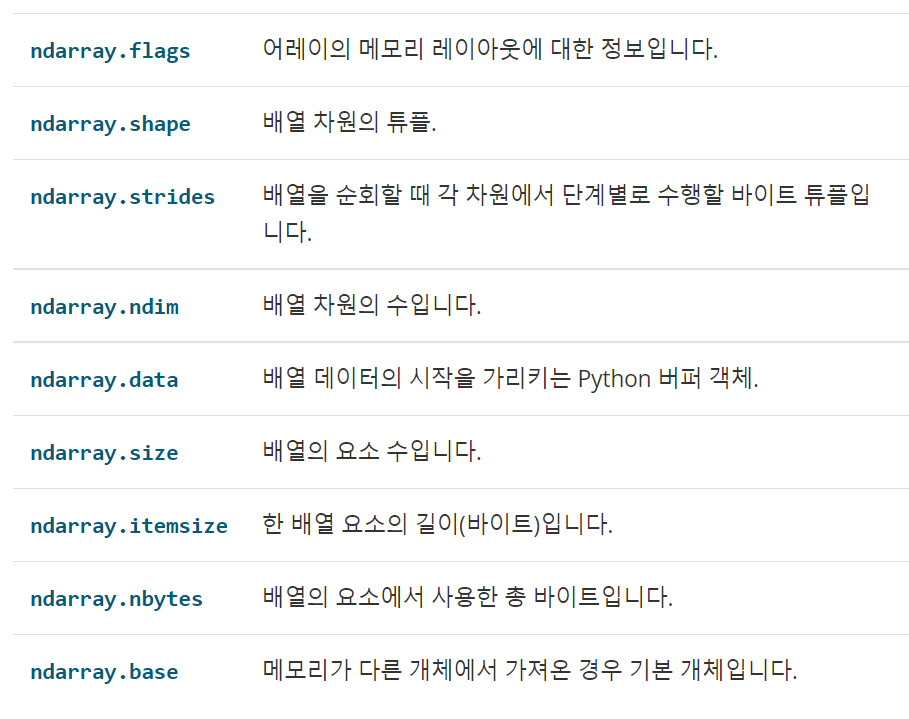
ndarray 배열은 각 차원의 크기를 알려주는 shape(튜플) 과 배열에 저장된 자료형을 알려주는 dtype 이라는 객체, 차원 ndim 을 가지고 있다. ndarray 속성은 다음과 같다.
2. ndarray 생성하기
Numpy 에서는 다양한 배열 생성 함수들을 제공한다.
Python List -> Ndarray
data1 = [1,2,3,4,5]
data2 = [[1,2,3,4], [5,6,7,8]]
# list -> ndarray
arr1 = np.array(data1)
arr2 = np.array(data2)
print(type(arr1)) # <class 'numpy.ndarray'>배열을 생성하는 방법으로는 파이썬의 순차적인 객체(List, Tuple 등 Sequence Data)를 넘겨주면, 넘겨 받은 데이터가 있는 새로운 Ndarray 배열을 생성한다. dtype을 명시하지 않은 경우 자료형을 추론하여 저장한다.
0 / 1 행렬 생성
# 0 행렬 생성
print(np.zeros(10))
print(np.zeros((3, 6)))
# 1 행렬 생성
print(np.ones((2,3)))empty()
# 메모리를 초기화 하지 않기 때문에 예상하지 못한 쓰레기 값이 들어가 있음.
print(np.empty((2, 3, 2)))*empty() 로 배열을 생성할 때 메모리를 초기화 하지 않기 때문에 예상치 못한 가비지 값이 들어가 있다.
arange()
arange는 파이썬 range 함수의 배열 버전이다. arange 로 배열을 생성할 경우 기본 dtype 은 int32 이다.
print(np.arange(15)) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]|
# reshape : 재배열
print(np.arange(15).reshape(3, 5))
# dtype
print(np.arange(10).dtype) # int32full(shape, element)
print(np.full((2,3), 5, dtype = np.int32))인자로 받은 dtype과 배열의 모양을 가지는 배열을 생성하고 인자로 받은 값으로 배열을 채운다.
eye(n, k), identity(n)
print(np.identity(3))
print(np.eye(3, k=1))
print(np.eye(3, k=-1))두 함수 모두 NxN 의 2차원 단위행렬을 생성한다. eye()의 k 는 단위행렬을 기준으로 어느 부분에 대각행렬을 나타낼껀지 결정하는 값이다. 실행 결과를 확인해보자.
실행결과

3. Ndarray dtype
dtype은 ndarray가 메모리에 있는 특정 데이터를 해석하기 위해 필요한 정보를 담고 있는 특수한 객체이다.
arr1 = np.array([1,2,3], dtype = np.float64)
arr2 = np.array([1,2,3], dtype = np.int32)
print(arr1.dtype)
print(arr2.dtype)Numpy 에서 제공하는 데이터 타입은 다음 글을 참고하길 바란다.
형변환
ndarray의 astype 메서드를 사용하여 배열의 dtype을 다른 형으로 명시적으로 변환 가능하다.
arr = np.array([1,2,3,4,5])
float_arr = arr.astype(np.float64)
arr = np.array([2.6, 3.1, 5.2])
print(arr.astype(np.int32)) # [2 3 5]
# string -> float
numeric_strings = np.array(['1.24', '-2.4', '24'], dtype=np.string_)
print(numeric_strings.astype(float))# [ 1.24 -2.4 24. ]* float -> int 형으로 변환 시 소수점은 버려진다.
# 축약
zeros_uint16 = np.zeros(5, dtype='u2')
print(zeros_uint16.dtype)dtype으로 'u2' 와 같은 축약 코드도 사용 가능하다.
4. 배열의 산술 연산
기본 배열 연산
우선 행렬을 생성하고 행렬의 곱, 행렬의 합, 행렬의 제곱 등 다양한 산술 연산을 해보겠다.
data = np.array([[1., 2., 3.], [4., 5., 6.]])
print(data)
# 행렬 곱
print(data*10)
# 행렬 합
print(data + data)
# 행렬 n제곱
print(arr * arr)
print(arr ** 2)
# 역수
print(1/arr)실행결과

배열 간의 비교 연산 (같은 크기)
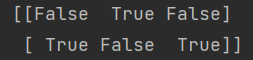
arr = np.array([[1., 2., 3.], [4., 5., 6.]])
arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
print(arr2 > arr)같은 크기를 가지는 배열 간의 비교 연산은 불리언 배열을 반환한다.
cf > 크기가 다른 배열 간의 연산(브로드캐스팅)은 새 글로 자세히 다루겠다.
5. 색인과 슬라이싱
데이터의 부분집합이나 개별 요소를 선택하기 위한 수많은 방법을 알아보자.
1차원 색인 / 슬라이싱 기초
arr = np.arange(10)
# element indexing
print(arr[5]) # 5
# slicing
print(arr[5:8]) # [5 6 7]
arr[5:8] = 12 # [ 0 1 2 3 4 12 12 12 8 9]
# : is all elements
arr[:] = 0슬라이싱 할 때 주의할 점이 있다. 예시를 통해 확인해보자.
arr_slice = arr[2:4]
arr_slice[:] = 16
print(arr) # [ 0 1 16 16 4 5 6 7 8 9]arr_slice 변수에 슬라이싱한 arr를 담고 값을 바꾸면 원래 배열인 arr의 값이 바뀐다.
원래 배열은 그대로 두고 값만 복사해서 바꾸고 싶다면 copy() 함수를 사용해야한다.
# copy() : 새로운 ndarray 객체에 값을 복사.
arr_slice = arr[2:4].copy()N차원 색인 / 슬라이싱 기초
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print(arr2d[2]) # [7 8 9]
print(arr2d[0][2]) # 3
print(arr2d[0, 2]) # 3
print(arr2d[:,1]) # [2 5 8]
print(arr2d[:1] # [[1 2 3], [4 5 6]]
print(arr2d[:,:2]) #[[1 2], [4 5], [7 8]]
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10,11,12]]])
print(arr3d[0]) # [[1, 2, 3], [4, 5, 6]]
print(arr3d[0][1]) # [4, 5, 6]
print(arr3d[0, 1]) # [4, 5, 6]
print(arr3d[0][1][2]) # 6
print(arr3d[:,1]) # [[ 4 5 6], [10 11 12]]행/렬 순으로 접근한다. 위 예시들을 이해하면 슬라이싱에 대한 감을 잡을 수 있을 것이다.
6. 불리언값으로 선택하기
불리언값으로 인덱싱하는 방법에 대해 알아보자.
Data
alphabet = np.array(['a','b','c','d', 'a', 'a', 'b'])
data = np.random.randn(7,4)중복이 있는 알파벳 배열과 np.random 모듈에 있는 randn 함수를 사용해서 만든 임의의 표준 정규 분포 데이터이다.
각 알파벳은 Data 의 Row 에 대응한다.
비교 연산자로 값 비교
print(alphabet == 'a') # [ True False False False True True False]
print(alphabet != 'a') # [False True True True False False True]
print((alphabet == 'a') | (alphabet == 'b')) # [ True True False False True True True]
print((alphabet == 'a') or (alphabet == 'b')) # Error!배열에 대한 비교 연산으로 비교하면 불리언 배열을 반환한다.
cf> 파이썬 예약어인 and 와 or 은 불리언 배열에서 사용할 수 없다. 대신 & 와 | 를 사용하면 된다.
불리언 배열로 인덱싱
위 예시의 불리언 배열로 data를 인덱싱해보자.
print(data[alphabet == 'a']) # index = 0,4,5 인 행
print(data[~(alphabet == 'a')]) # ~ 를 통해 부정 / index = 0,4,5 외 나머지 행
print(data[alphabet == 'a', 2:]) # index = 0,4,5 인 행에서 3번째 element 부터 끝부정을 할 때 ~ 또는 != 를 이용하면 된다. 기본적인 인덱싱에 불리언으로도 데이터를 선택할 수 있다는 것을 기억하자.
이를 이용해서 데이터의 음수를 특정 값으로 바꾸거나 1차원 배열을 사용해서 전체 로우나 컬럼을 선택하는 것을 쉽게 할 수 있다.
data[data < 0] = 0 # 모든 음수 데이터에 0 대입이런 유형의 계산은 Pandas 라이브러리를 이요해서 처리하는 것이 편리하다.
7. 팬시 색인
팬시 색인은 정수 배열을 사용한 색인이다.
Data
arr = np.empty((5,4))
for i in range(5):
arr[i] = i
"""
[[0. 0. 0. 0.]
[1. 1. 1. 1.]
[2. 2. 2. 2.]
[3. 3. 3. 3.]
[4. 4. 4. 4.]]
"""
arr2d = np.arange(32).reshape((8, 4))
"""
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]
[16 17 18 19]
[20 21 22 23]
[24 25 26 27]
[28 29 30 31]]
"""특정 순서로 로우 선택
print(arr[[4,3,0,2]])
"""
[[4. 4. 4. 4.]
[3. 3. 3. 3.]
[0. 0. 0. 0.]
[2. 2. 2. 2.]]
"""
print(arr[[-1,-2,-3,-4]]) # 음수를 통해 역순
"""
[[4. 4. 4. 4.]
[3. 3. 3. 3.]
[2. 2. 2. 2.]]
"""배열에 원하는 순서의 정수 리스트(혹은 ndarray)를 넘겨주면 된다. 음수를 통한 역순도 가능하고 부분적으로 데이터를 불러오는 것도 가능하다.
다차원 색인 배열(리스트를 두개 넘기는 등) 을 넘기는 것은 조금 다르게 동작하기 때문에 이것에 대해 알아보자.
print(arr2d[[1,5,7,2], [0,3,1,2]]) # [ 4 23 29 10] 4: arr[1][0] 23: arr[5][3] ...
"""
[ 4 23 29 10]
"""
print(arr2d[[1, 5, 7, 2]][:, [0, 3, 1, 2]]) # 1 행에서 0,3,1,2 data 5행 에서 0,3,1,2 data...
"""
[[ 4 7 5 6]
[20 23 21 22]
[28 31 29 30]
[ 8 11 9 10]]
"""리스트를 ,로 두개를 넘겨줄 경우 (1,0), (5,3) 에 해당하는 element들이 선택된다. 각 행에서 원하는 데이터를 가져오고 싶다면 두 번째 방법처럼 사용하면 된다.
팬시 색인은 슬라이싱과는 달리 선택된 데이터를 새로운 배열로 복사한다.
CopyOfArr = arr[[4,3,0,2]]
CopyOfArr[1] = 7
print(CopyOfArr)
"""
[[4. 4. 4. 4.]
[7. 7. 7. 7.]
[0. 0. 0. 0.]
[2. 2. 2. 2.]]
"""
print(arr)
"""
[[0. 0. 0. 0.]
[1. 1. 1. 1.]
[2. 2. 2. 2.]
[3. 3. 3. 3.]
[4. 4. 4. 4.]]
"""8. 배열 전치와 축 바꾸기
배열 전치는 데이터를 복사하지 않고 데이터의 모양이 바뀐 뷰를 반환하는 기능이다. ndarray는 transpose 메서드와 T라는 이름의 속성을 가지고 있다.
Data
arr = np.arange(15).reshape((3, 5))
print(arr)
"""
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
"""
arr2 = np.arange(16).reshape((2, 2, 4))전치
print(arr.T) # (5,3)
"""
[[ 0 5 10]
[ 1 6 11]
[ 2 7 12]
[ 3 8 13]
[ 4 9 14]]
"""내적
# np.dot 을 이용한 행렬의 내적 구하기
print(np.dot(arr.T, arr))
"""
[[125 140 155 170 185]
[140 158 176 194 212]
[155 176 197 218 239]
[170 194 218 242 266]
[185 212 239 266 293]]
"""transpose()
# transpose() : 다차원 배열에서 치환
print(arr2)
"""
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
"""
print(arr2.transpose((1, 0, 2)))
"""
[[[ 0 1 2 3]
[ 8 9 10 11]]
[[ 4 5 6 7]
[12 13 14 15]]]
"""transpose 메서드는 튜플로 축 번호를 받아서 치환한다.
swapaxes()
print(arr2.swapaxes(1,2))
"""
[[[ 0 4]
[ 1 5]
[ 2 6]
[ 3 7]]
[[ 8 12]
[ 9 13]
[10 14]
[11 15]]]
"""T 속성을 이용한 간단한 전치는 축을 뒤바꾸는 특별한 경우라고 한다. swapaxes 메서드는 두 개의 축 번호를 받아서 배열을 뒤바꾼다. (swapaxes 데이터 복사 x, 뷰 반환)
이 부분에 대한 완벽한 이해는 선형대수를 배운 후 더 자세히 알아보자.
참고 자료
[Numpy 공식 문서] : https://numpy.org/doc/stable/reference




