
/* 본 게시물은 ' 파이썬 라이브러리를 활용한 데이터 분석 2판 | with 웨스 맥키니 ' 의 내용과 참고자료를 토대로 작성되었습니다. */
/* 본 글은 개인적으로 공부한 내용을 정리한 글이므로 오류가 있을 수 있습니다. */
DataFrame
1. DataFrame 이란?
DataFrame 은 표 같은 스프레드시트 형식의 자료구조이다. (엑셀을 생각하면 된다.) 여러 개의 칼럼이 있는데 각 칼럼은 서로 다른 종류의 값(숫자, 문자열, 불리언 등)을 담을 수 있다. DataFrame은 로우와 컬럼에 대한 색인을 가지고 있는데, 색인의 모양이 같은 Series 객체를 담고 있는 다른 컬렉션이 아니라 하나 이상의 2차원 배열에 저장한다.
2. DataFrame 다루기
DataFrame 객체 생성하기
DataFrame 객체를 생성하는 가장 흔한 방법은 같은 길이의 리스트에 담긴 사전을 이용하거나 Numpy 배열을 이용하는 것이다.
# 리스트의 길이가 같아야 됨.
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2000, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)
# 파이썬의 Dictionary -> DataFrame
frame = pd.DataFrame(data)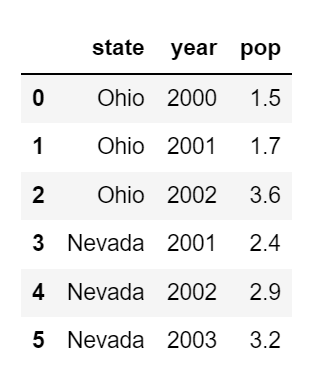
DataFrame 의 색인은 기본적으로 Seires와 같이 자동으로 대입되며 컬럼은 정렬되어 저장된다.
head()
head 메서드는 처음 5개의 로우를 출력한다.
# 상위 5개 자료 출력
frame.head()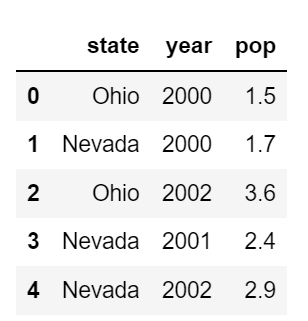
컬럼 순서 지정
# columns 키워드를 통해 순서 지정 가능
pd.DataFrame(data, columns=['year', 'state', 'pop'])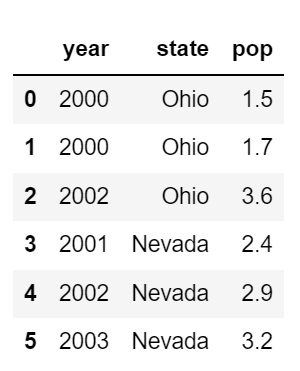
결측치
# Columns 키워드를 통해 원하는 컬럼을 가져올 수 있음
# index 키워드를 통해 색인 지정 가능
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four',
'five', 'six'])
frame2
debt 컬럼의 데이터는 NaN 이 저장된 것을 확인할 수 있다.
컬럼 데이터 접근 및 바꾸기
Series 처럼 사전 형식의 표기법으로 접근하거나, 속성 형식으로 접근 가능하다.
# 사전 형식 표기법으로 접근
frame2['state']
# 속성 접근
frame2.year
type(frame2['state'])
type(frame2.year)
각 컬럼은 Series 형인 것을 확인 할 수 있다.
컬럼 데이터 변경 및 추가하기
frame2['debt'] = 16.5
frame2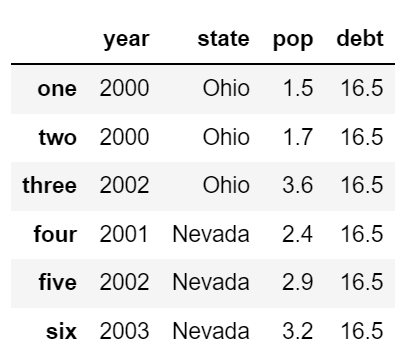
스칼라 값을 넣으면 모든 index 에 같은 값을 추가한다.
frame2['debt'] = np.arange(6.)
frame2
같은 길이의 배열을 넣어주면 각 index 에 해당하는 값을 추가한다.
val = pd.Series([1.2, 2.5, 4.7], index=['one', 'two', 'five'])
frame2['debt'] = val
frame2
없는 index 는 결측치가 자동으로 대입된다.
로우 데이터 접근
로우 데이터는 loc 속성을 이용해서 이름을 접근할 수 있다.
# loc() : 원하는 로우 데이터 접근
frame2.loc[['two', 'three']]
새로운 컬럼 생성하기
# Ohio 인지 에 대한 불리언을 추가한다
frame2['eastern'] = frame2.state == 'Ohio'
frame2
컬럼 삭제하기
del 로 이용해서 컬럼을 삭제할 수 있다.
# column 삭제, 단 여러개 column 은 삭제 안됨. 하나씩 삭제 가능
del frame2['eastern']중첩된 사전을 이용한 DataFrame 객체 생성
# 중첩된 Dictonary Data
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
# Dictonary -> DataFrame
frame3 = pd.DataFrame(pop)
frame3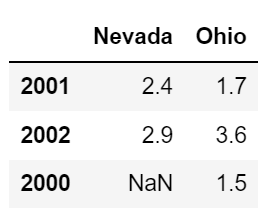
바깥 사전의 key -> 칼럼 / 안쪽 사전의 key -> 로우 가 되는 것을 확인 할 수 있다.
# 색인 직접 지정
pd.DataFrame(pop, index=[2001, 2002, 2003])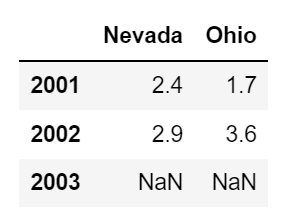
index 키워드를 사용하여 색인을 직접 바꿀수도 있다.
컬럼 로우 전치
# Numpy와 같은 방법으로 전치
frame3.T
컬럼 로우 이름 지정
# Seires 처럼 index 와 columns 에 이름 설정
frame3.index.name = 'year'
frame3.columns.name = 'state'
frame3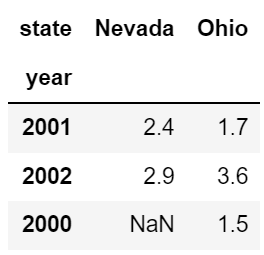
데이터 값만 추출하기
values 속성을 통해 값을 출력한다.
frame3.values
참고 자료
[Pydata Github ( 게시물 예시 )] : https://github.com/wesm/pydata-book




