
/* 본 게시물은 ' Introduction to MachineLearning with Python | 안드레이스 뮐러, 세라 가이도 ' 의 내용과 참고자료를 토대로 작성되었습니다. */
/* 본 글은 개인적으로 공부한 내용을 정리한 글이므로 오류가 있을 수 있습니다. */
1. 결정트리란?
결정트리는 분류와 회귀 문제에 널리 사용하는 모델이다. 기본적으로 결정 트리는 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습한다. (스무고개와 비슷하다.)
결정트리 장점
- 트리를 시각화하면 데이터가 어떻게 분류(예측)되는지 확인이 가능하다.
- 데이터의 스케일에 영향을 받지 않는다.
- 각 특성이 개별적으로 처리되어 데이터를 분할하는데 데이터 스케일의 영향을 받지 않으므로 결정 트리에서는 특성의 정규화나 표준화 같은 데이터 전처리 과정이 필요없다.
결정트리 단점
- 사전 가전치기를 사용해도 과대적합되는 경향이 있기 떄문에 일반화 성능이 좋지 않다.
- 트리 모델은 훈련 데이터 밖의 새로운 데이터를 예측할 능력이 없다.
결정 트리의 단점을 보완하기 위해 앙상블 기법을 사용한다. 앙상블에 대한 내용은 다음 게시글로 다루겠다.
2. 트리의 구조
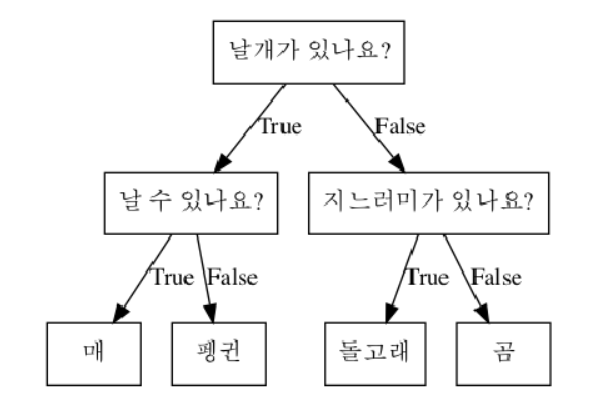
네모 상자를 노드라 부른다. 맨 처음 노드를 루트 노드, 마지막 노드는 리프라고 한다. 마지막 노드 중 타깃 하나로만 이루어진 경우 순수 노드라고 한다.
3. 결정 트리 다루기
결정 트리 과정 이해하기

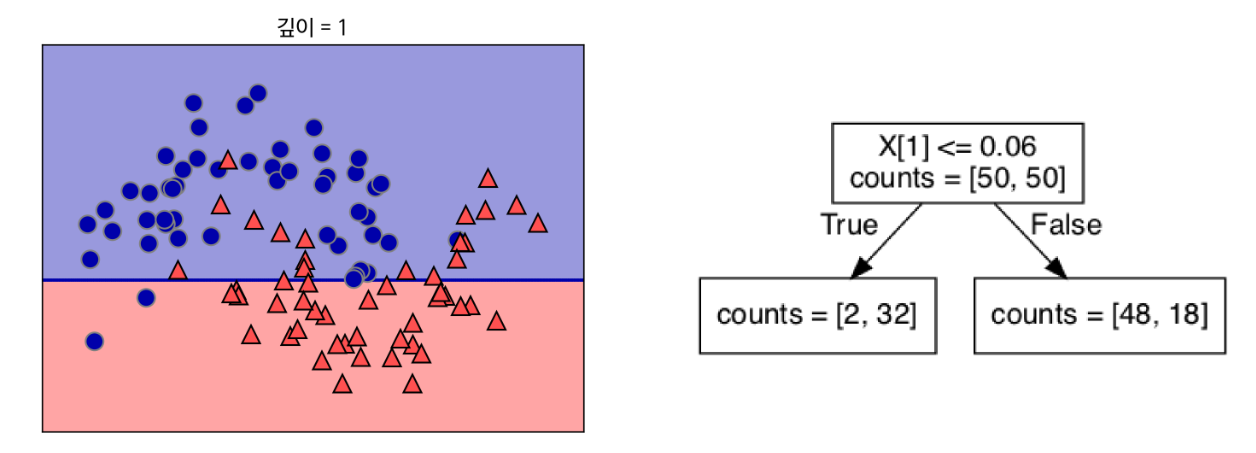

* 정보 이득이 최대가 되도록 분류한다. (정보 이득 = 부모 불순도 - 자식 노드 사이의 불순도 차이)
결정 트리 만들기
#데이터 셋 불러오기
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
#결정트리 생성 및 훈련
from sklearn.model_selection import train_test_split
train_input, test_input, train_label, test_label = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=42)
dt = DecisionTreeClassifier(random_state = 42)
dt.fit(train_input, train_label)
print("훈련 세트 정확도: {:.3f}".format(dt.score(train_input, train_label)))
print("테스트 세트 정확도: {:.3f}".format(dt.score(test_input, test_label)))
훈련 세트에 대해 100%의 정확성을 보아 과대적합이 일어난 것을 알 수 있다.
결정 트리 복잡도 제어하기
일반적으로 트리 만들기를 모든 리프 노드가 순수 노드가 될 때까지 진행하면 모델이 매우 복잡해지고 훈련 데이터에 과대적합된다. 위 예시처럼 훈련 세트에 100% 정확하게 맞는다. 이를 막기 위한 방법은 크게 두 가지이다. 트리 생성을 일찍 중단하는 방법(사전 가전치기)과 트리를 만든 후 데이터 포인트가 적은 노드를 삭제하거나 병합하는 방법(사후 가지치기)이 있다. DecisionTreeClassifier 는 max_depth 매개변수를 통해 사전 가전치기를 할 수 있다.
#max_depth 설정
dt_max_depth = DecisionTreeClassifier(max_depth=4, random_state=0)
dt_max_depth.fit(train_input, train_label)
print("훈련 세트 정확도: {:.3f}".format(dt_max_depth.score(train_input, train_label)))
print("테스트 세트 정확도: {:.3f}".format(dt_max_depth.score(test_input, test_label)))
트리 깊이를 4로 제한하여 과대적합을 줄였다. 테스트 세트 정확도가 이전보다 높아진 것을 확인할 수 있다.
결정 트리 분석
트리를 시각화 하는 방법은 2가지가 있다. 첫 번째로는 graphviz 라이브러리를 사용한 방법, 두 번째로는 plot_tree 메서드를 사용한 방법이 있다. 이번 예시로는 두 번째 방법을 사용하겠다.
# 방법2. plot_tree 메서드 사용
from sklearn.tree import plot_tree
# class_names : 노드 클래스, filled : 클래스 별 색 구별
plot_tree(dt_max_depth, class_names=["악성", "양성"], feature_names=cancer.feature_names, impurity=False,
filled=True, rounded=True, fontsize=4)
plt.show()
* 사용한 feature 에 따라 색이 다르다.
트리의 특성 중요도
트리를 만드는 과정에서 각 특성이 얼마나 중요한지 평가하는 특성 중요도를 확인해보자.
print("특성 중요도:\n", dt_max_depth.feature_importances_)
값이 0~1 사이에 존재한다. 각 특성에 대해 0은 트리를 만드는데 전혀 사용되지 않았다는 의미이고, 1은 완벽하게 타깃 클래스를 예측했다는 의미이다. 특성 중요도의 전체 합은 1이다. 특성 중요도를 시각화해보자.
def plot_feature_importances_cancer(model):
# feature 개수
n_features = cancer.data.shape[1]
print(n_features)
print(np.arange(n_features))
plt.barh(np.arange(n_features), model.feature_importances_, align='center')
plt.yticks(np.arange(n_features), cancer.feature_names, fontname= "Arial")
plt.xlabel("특성 중요도")
plt.ylabel("특성")
plt.ylim(-1, n_features)
plt.show()
plot_feature_importances_cancer(dt_max_depth)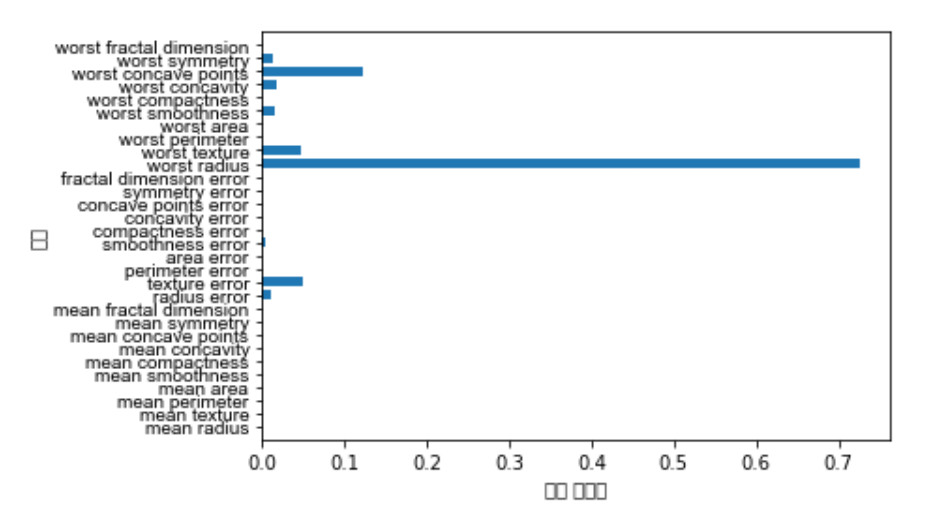
참고 자료
[URL] :
