
이번 게시글에서는 R에서 가장 기초가 되는 변수와 기본 데이터 타입, 연산자에 대해 알아보겠습니다.
1. 변수
`변수`란 변할 수 있는 데이터를 말합니다. R에서는 데이터 분석의 대상이 되는 데이터를 의미합니다.
반대되는 개념으로는 상수가 있죠. R에서의 상수 개념은 기존의 다른 프로그래밍 언어의 상수(변하지 않는 값) 의미와는 다른데요.
R에서의 `상수`는 데이터의 속성이 하나의 값으로 이루어져 있어 데이터 분석을 할 가치가 없는 데이터를 의미합니다.
변수 선언과 대입
변수를 선언하는 방법은 다음과 같습니다.
var <- 1
print(var)R에서는 변수 선언과 동시에 할당을 해주어야 합니다. 또한, 특이하게도 변수를 할당할때는 `<-` 를 사용합니다.
변수 할당에 `=`를 사용해도 문제 없지만, 대부분 `<-` 를 많이 사용하는데요. 하나의 방식으로 통일하길 추천드립니다.
변수명 규칙
변수명은 다음과 같은 규칙을 따릅니다.
- `알파벳`, `숫자`, `_`, `.` 을 조합하여 변수명으로 사용할 수 있습니다.
- `-` 는 변수명에 사용불가능합니다.
- 첫글자는 `알파벳` 또는 `.`로 시작해야합니다 (숫자로 시작 불가능). 단, .로 시작하면 뒤에 숫자는 올 수 없습니다.
- 대소문자를 구분합니다.
변수명 예시
- 영문만 이용 (ex. x, var)
- 영문과 숫자 (ex. x1, var1)
- 영문과 . 조합 (ex. x.mean)
2. 기본 데이터 타입
R에서는 변수 타입을 `mode`라고 부르는데요. 이번에는 R의 기본 데이터 타입(mode)에 대해 알아보겠습니다.
R의 대표적인 기본 데이터 타입으로는 다음과 같습니다.

이러한 데이터 타입의 원소가 모여 나중에 배울 벡터, 배열, 행렬 등의 데이터 컬렉션을 형성하게 됩니다.
위 데이터 타입 중에 몇가지만 다뤄보겠습니다.
1) 정수, 실수
숫자형 데이터에 대해 알아보겠습니다. 숫자형 데이터는 `정수형`과 `실수형`으로 나뉘는데요.
다음 예제들을 통해 이해해보겠습니다.
num1 <- 10000
print(num1)
num2 <- 100000
print(num2)
num3 <- 1e5
print(num3)
num4 <- 12345678910
print(num4)
코드 결과는 위와 같습니다.
num1을 확인하면 분명 10000까지는 제대로 출력하는데 100000은 1e+05로 출력하네요.
이는 표기상 더 간결하게 나타내기 위해 e(0의 개수)로 자동으로 변환한 것을 알 수 있네요.
따라서 num3 처럼 변수에 1e5로 넣어도 동일한 결과를 출력합니다. 여기서 1e+05는 정수 100000입니다.
물론 num4 처럼 간결하게 표현할 수 없는 수는 그대로 출력합니다.
그렇다면 아래 1234567891234처럼 큰 수는 어떻게 출력될까요?
num <- 1234567891234
print(num)
무언가 이상한 점을 알아차리셨나요? 네 아마 다른 프로그래밍 언어를 배우신 분들이라면 이미 눈치를 채셨을 것 같은데요. 1234567891234가 소수(실수)로 표현되었습니다.

실제로 `typeof()`를 이용해 데이터 타입을 출력해보면 `double`(실수)로 출력되는 것을 확인할 수 있습니다.
이는 자신의 운영체제(32비트, 64비트)에 따라 정수형의 범위가 다르기 때문입니다.
여기서 재미있는 사실은 만약 여러분의 운영체제가 32비트였다면, 위에서 정수로 출력된 12345678910도 실수로 출력되었을 것 입니다!
이번에는 실수형 변수를 만들어보겠습니다.
double1 <- 1.23456
print(double1)
double2 <- 1.23456789123
print(double2)
double3 <- 1e-4
print(double3)
print(typeof(double3))
위 결과에서도 재미있는 사실 하나를 알 수 있습니다. `double2`의 출력결과를 확인하면, R console 창에서 소수를 출력할 때 특정 소수점 이하로는 잘리는 것을 확인할 수 있습니다.
그렇다면 아래 코드의 결과는 어떻게 될까요?
double4 <- 1.2345678
print(double2 == double4)
네 어떻게 보면 당연하게도 FALSE를 출력하게 되는데요. 여기서 조심할 점은 출력된 값이 같더라도 실제로는 값이 다를 수 있다는 점입니다.
나중에 자세히 배우겠지만 만약 실수형 데이터를 인덱스로 설정할 시, 이러한 이유로 우리가 원하는 값을 못 찾는(인덱싱되지 않는) 문제가 발생할 수 있습니다. 따라서, 실수형 데이터를 인덱스로 설정할 때는 반올림으로 먼저 소수점을 처리하는 방법 등 주의가 필요합니다.
산술 연산자

비교 연산자

2) 논리형
TRUE
T
# True (x)
FALSE
F
# False (x)흔히 다른 프로그래밍 언어에도 있는 논리(Boolean)형 입니다. 특이한 점은 `TRUE`, `T`, `FALSE`, `F` 처럼 모두 대문자로 표기해야 한다는 것입니다.
논리 연산자

R에서의 논리 연산자는 위 표와 같습니다.
3) 인자 (Factor)
저는 R을 배우면서 인자(Factor)형이 제일 생소했는데요. `Factor` 는 범주형 데이터를 표현하기 위한 데이터 타입입니다. 그리고 `범주형`은 다시 `명목형` (ex. 남/녀)과 `순서형`(ex. 성적: A, B, C) 데이터로 나눠집니다.
먼저, 명목형 데이터를 생성하는 방법을 알아보겠습니다.
# factor 생성
gender <- factor("m", c("m","f"))
print(gender)
`factor({특정 level}, {Level})`를 통해 factor를 생성할 수 있습니다. 여기서 특정 level는 특정 카테고리, Level은 남,녀 처럼 카테고리라고 이해하면 됩니다. 다시 한번 `Factor`는 특정 level과 같은 범주형 데이터라는 것을 꼭 기억해주세요!
벡터 c()에 대해서는 다음 게시글에서 자세히 다루기 때문에 지금은 이런게 있다 정도로 이해하고 넘어가주세요!
다음으로는 순서형 데이터를 생성하는 방법을 알아보겠습니다.
# 방법1
grade <- ordered("A", c("A", "B", "C"))
# 방법2
grade <- factor("A", c("A", "B", "C"), ordered=TRUE)
`ordered()`와 `factor()`를 이용하여 순서형 데이터를 만들 수 있는데요. 여기서 주의할 점은 벡터(c)의 인자 순서대로 level 순이 결정된다는 것입니다.
따라서, C < B < A 순의 레벨을 만들고 싶으면 다음과 같이 코드를 작성하면 됩니다.
grade <- ordered("A", c("C", "B", "A"))
추가적으로 팩터와 레벨을 다루는 방법들을 소개하겠습니다.
# level 수
nlevels(gender)
#레벨 값의 변경 m -> male / f -> female
levels(gender) <- c("male", "female")
print(gender)
# 여러 개 값을 팩터로 만들때는 벡터 사용
factor(c("m", "f", "f"), c("m", "f"))
# level 인자 없으면 데이터로부터 자동 생성
gender <- factor(c("m", "f", "n"))
levels(gender)
# 팩터인지 확인
print(is.factor(grade))
# 순서형 데이터인지 확인
print(is.ordered(gender))
4) NA / NULL / NaN
- `NULL` : 비어있다는 의미로 대상이 없음을 뜻합니다.
- `NA`: Not Available로 사용할 수 없는 데이터를 뜻하며, 일반적으로 결측값을 의미합니다.
- `NAN`: Not a Number로 정의 되지 않거나 할 수 없는 결과를 수학 연산으로 나타내는데 사용합니다. (ex. 0 / 0)
아래 코드 결과를 통해 쉽게 정리하면,

- `NULL`: 값이 들어갈 자리조차 없다.
- `NA`: 값이 들어갈 자리는 있는데 값이 없다.
- `NaN`: 값이 들어갈 자리가 있는데 값이 계산상의 오류 때문에 계산되지 않아 값이 없다.

위에서 언급한 것처럼 R에서는 변수를 생성할 때 선언과 할당을 동시에 해야했습니다. 그런데 프로그래밍을 하다보면 변수를 먼저 선언하고 (만들어놓고) 후에 변수에 값을 할당하고 싶은 경우가 많이 생기는데요. 이 경우 NULL을 변수에 대입한 후 나중에 값을 넣어주면 됩니다.
추가적으로 NA 처리 방법에 대해 궁금하시면 다음 글을 참고해주세요.
데이터 타입 변환하기

`as.{변환할 유형}`을 통해 데이터 타입을 변경할 수 있습니다. 예시는 다음과 같습니다.
x <- 1
x <- as.character(x)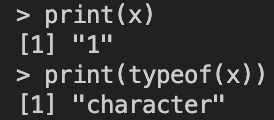
정수형 변수 x가 1 에서 ""로 감싸인 문자열 "1"로 변환된 것을 확인할 수 있습니다. 추가로 x에 벡터를 넣어도 벡터내 원소들이 모두 변환됩니다.
이상으로 이번 글을 마무리하겠습니다. R에 대한 정리본을 확인하고 싶으면 다음 글을 참고바랍니다.
참고자료
1. NULL / NA / NAN 차이 : https://m.blog.naver.com/plasticcode/222712258423




